Данный документ является неофициальным переводом исходной английской версии A Semantic Web Primer for Object-Oriented Software Developers и может содержать неточности и ошибки. Оригинальный документ на английском языке, расположенный на сайте W3C, является единственно официальным. © Владимир Сибиров (vladimir dot sibirov at kodigy dot com).

Введение в семантическую паутину для разработчиков объектно-ориентированного программного обеспечения
Заметка рабочей группы W3C, 9 марта 2006
- Данная версия:
- http://www.w3.org/TR/2006/NOTE-sw-oosd-primer-20060309/
- Текущая версия:
- http://www.w3.org/TR/sw-oosd-primer/
- Предыдущая версия:
- Это первая опубликованная версия
- Редакторы:
- Хольгер Кнублаух, Манчестерский университет <holger@knublauch.com>
Даниэль Оберле, Университет Карлсруэ <oberle@fzi.de>
Фил Тетлоу, IBM
<philip.tetlow@uk.ibm.com>
Эван Уоллес, Национальный институт стандартов и технологии <ewallace@cme.nist.gov>
- Участники:
- Джефф З. Пэн, Абердинский университет (ранее Манчестерский университет), <jpan@csd.abdn.ac.uk>
- Майкл Ушолд, Boeing, <michael.f.uschold@boeing.com>
-
- Смотрите также Благодарности.
Copyright © 2006 W3C® (MIT, ERCIM, Keio), все права защищены. Применяются все нормативы W3C, связанные с ответственностью, торговыми марками и использованием документов.
Аннотация
Модели предметной области играют центральную роль на протяжении всего цикла разработки программного обеспечения, от анализа требований к проектированию, на протяжении реализации и далее после неё. По существу, огромный прогресс достигнут в целостном использовании моделей на протяжении этого процесса. Современные инструменты разработки программного обеспечения с поддержкой UML и генерации кода, а также архитектур, основанных на моделях, позволяют разработчикам синхронизировать и сверять техническую реализацию с требованиями пользователей, используя модели. Тем не менее, повторное использование моделей предметной области часто оказывается затруднено, потому что они по определению специфичны для предметной области и принимают в рассмотрение только абстракции, необходимые для того, чтобы сделать решение возможным в рамках их собственной проблемной области. Но всемирная паутина шире этого и предоставляет многомерное пространство решения проблем, способное связывать почти неограниченное множество предметных областей. В то время, как большая часть нашего программного обеспечения становится всё более встроенной в Веб, наши процессы разработки пока ещё не полностью используют потенциал повторного использования моделей из Паутины. Эта статья, следовательно, представляет вашему вниманию языки семантической паутины (Semantic Web), такие как RDF Schema и OWL, и показывает, как они могут быть использованы в тандеме с господствующими объектно-ориентированными языками. Мы покажем, что семантическая паутина может выступать в роли платформы, на базе которой модели предметной области могут создаваться, распространяться и использоваться повторно.
Статус данного документа
Данная секция описывает статус этого документа на момент его публикации. Другие документы могут заменить собой этот документ. Список текущих публикаций W3C и последнюю версию данного технического доклада можно найти в индексе технических докладов W3C по адресу http://www.w3.org/TR/.
Этот документ был создан Software Engineering Task Force (SE)
из W3C Semantic Web
Best Practices and Deployment Working Group (SWBPD).
Данная работа является частью W3C
Semantic Web Activity.
Данный документ является заметкой рабочей группы W3C, и рабочая группа SWBPDна данный момент более не планирует создания новых его версий.
Комментарии приветствуются и могут быть отправлены по адресу public-swbp-wg@w3.org; пожалуйста, укажите слово «комментарий» в теме письма. Все сообщения, получаемые по этому адресу, можно просмотреть в
общедоступном архиве. Читатели, заинтересованные в данной тематической области, могут также следить за обсуждениями в почтовом архиве Группы интересов семантической паутины и участвовать в них.
Этот документы был создан группой, действующей на основании Патентной политики W3C от 5 февраля 2004 года. Данный документ носит исключительно информационный характер и, следовательно, не содержит связанных с ним обязательств Патентной политики W3C. У W3C есть общедоступный список любых патентных разглашений, сделанных в связи с результатами работы группы; та страница также содержит инструкции по разглашению патентов.
Публикация в качестве Заметки рабочей группы не влечет за собой подтверждение членами W3C. Это черновой документ, который может быть обновлен, заменен или выведен из обращения другими документами в любое время. Неверно цитировать данный документ иначе как черновой вариант.
1 Введение
Как правило, программные системы строятся вокруг моделей предметной области для представления аспектов их целевого проблемного поля. Модели предметной области могут описывать подходящие концепции и структуры данных из прикладной области и включать знание, полезное для реализации поведения приложения. Например, предположим, что наша задача заключается в разработке системы онлайн-продаж. Во время анализа требований для этой системы мы могли бы узнать, что:
-
- Заказы товаров (Purchase orders) связывают покупателя (Customer) со списком продуктов (Product)
- У покупателей есть страна проживания (Country)
- Германия, Франция и Австралия - страны
- Германия и Франция входят в Европейский Союз
- Европейский Союз — зона свободной торговли
- Заказы от покупателей, живущих в стране, заключившей соглашение о свободной торговле со страной онлайн-магазина, не облагаются пошлиной
После некоторого обдумывания мы можем прийти к объектно-ориентированной концепции, такой, как показано на следующей UML-диаграмме классов.
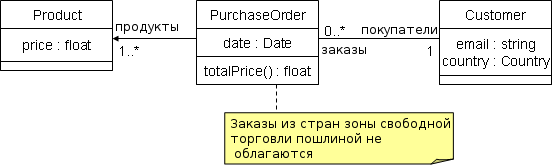
Рисунок 1: Простая модель предметной области на языке UML.
Мы можем представить эту схему нашему заказчику для обсуждения и после нескольких итераций мы, возможно, придём к структуре данных, которая может быть реализована на предпочитаемом нами языке программирования. Мы можем также начать с компонентов интерфейса для конечных пользователей (возможно, JavaServer Pages) и для управляющих онлайн-магазином (которые могут требовать более сложный интерфейс, реализованный, к примеру, на Java/Swing, C# или Visual Basic). Если наша система успешно пройдёт испытания, на её основе смогут быть построены новые компоненты, например, для доступа к каталогу продуктов через веб-службу. В этом случае другие компоненты захотели бы совместно использовать одни и те же структуры данных и прикладные знания таким образом, чтобы они могли взаимодействовать. Даже если наша система окажется не столь удачной или она будет портироваться на другую платформу, мы можем по меньшей мере захотеть повторно использовать её части. В таких случаях было бы полезно иметь доступ к нижележащей модели предметной области так, чтобы мы могли извлечь необходимые нам части.
Поскольку все эти потенциальные направления разработки ожидаемы, мы проектируем нашу систему на базе архитектуры Модель-Вид-Контроллер [BMRSS
1996]. Этот хорошо известный шаблон проектирования предлагает отделение моделей предметной области от пользовательского интерфейса и управляющей логики. Отделение не визуальных частей от визуальных компонентов потенциально облегчает повторное и совместное использование прикладных моделей другими приложениями и на других целевых платформах. К сожалению, обещание возможности повторного использования объектно-ориентированных моделей выполняется нечасто. Во многих случаях модели предметной области вроде той, что представлена выше, содержат жёстко закодированные зависимости от конкретного приложения. Особенно после того, как модель закодирована на языке программирования, большая часть знания, заключённого в оригинальном проекте, теряется. Например, условие того, является ли заказ товара беспошлинным, может быть заключено в if-выражениях глубоко внутри некоторого императивного метода (такого как totalPrice() на UML-диаграмме), и тот факт, что каждый PurchaseOrder требует наличия как минимум одного продукта, будет неясен, если вы не удосужитесь прочитать управляющую логику реализации пользовательского интерфейса. Другая типичная проблема таких систем — это взаимодействие. Например, если какое-то другое приложение захочет предоставить интерфейс к данным или службам из вашей системы, ему понадобится тщательно разобраться в подробно определённом программном интерфейсе (API), который строго связан с вашим приложением. Возможно использование промежуточного формата, основанного на XML, для обмена информацией между такими приложениями. Если множество приложений со схожими задачами должны будут взаимодействовать, понадобится большое количество таких интерфейсов и форматов обмена.
UML-диаграмма предоставляет огромный потенциал для повторного использования и взаимодействия в нашем примере. Такие диаграммы моделируют высокий уровень абстракции и могут быть использованы для построения на их основе кода реализаций для различных целей. Несмотря на это, даже если два компонента или приложения были начаты с одной и той же UML-диаграммы, они могут иметь несовместимые реализации. Потребуется всё ещё большое количество вручную написанного кода для их реализации. В каком формате данные клиента будут храниться и распространяться? Модель UML может оказаться неоднозначной и понятой неправильно. В одной реализации страны могут храниться как строковые значения, в то время как другие могут пожелать представить их в виде экземпляров класса Country. В любом случае, остаётся неясным, где и как отдельные страны, такие как Германия и Франция, будут представлены в UML. Более того, пока проект не следует целостному подходу на базе моделей, UML-диаграммы зачастую поддерживаются только как промежуточные артефакты в ходе разработки, используемые в качестве фундамента для реализации, но затем хранимые в таком месте, где они недоступны другим разработчикам. UML-модели зачастую прячут небезосновательно, поскольку они могут более не соответствовать действительной реализации. Результатом таких реалий разработки программного обеспечения является большая трата времени на ненужную дублирующую работу. Модели предметной области нужно конструировать с чистого листа вначале, а затем переводить их в промежуточные форматы для распространения данных среди приложений.
В идеальном случае разработчики могли бы находить общие прикладные модели и базы знаний во множестве взаимосвязанных репозиториев и затем связывать эти модели с оставшимися объектно-ориентированными компонентами пользовательского интерфейса и управляющими компонентами — это концепция, которая постепенно становится известной как архитектура, основанная на онтологиях (Ontology Driven Architecture). Все приложения, совместно использующие модели пересекающихся предметных областей, могли бы в таком случае автоматически получить определённую степень возможности взаимодействия. Пока этот идеальный случай остаётся по большей мере видением, начинают появляться некоторые многообещающие подходы [TPOWUK 2005].
Относительно незаметно для стана основных компаний-разработчиков программного обеспечения, Консорциум World Wide Web (W3C) разработал несколько очень интересных технологий в контексте своего видения семантической паутины (см. W3C Semantic Web Activity). Эти технологии, включая RDF [RDF 2004] и OWL [OWL 2004], изначально были спроектированы в целях облегчения понимания веб-страниц интеллектуальными агентами и веб-сервисами. Что интересно, оказывается, что языки и инструменты семантической паутины могли бы также играть важную роль в разработке программного обеспечения в целом.
Сообщество семантической паутины выпустило набор взаимодополняющих языков и инструментов для разработки, поддержки, использования и распространения моделей предметной области для проектирования программного обеспечения, а также прочих целей. В самом центре находятся такие языки, как OWL и RDF Schema, где OWL оптимизирован для представления структурных знаний на высоком уровне абстракции. Модели предметной области, выраженные на языке OWL, могут быть загружены в Сеть и совместно использованы многими приложениями. OWL поддерживается однозначным диалектом формальной логики, известной как Дескрипционная логика (Description Logics) [BHS 2003]. Это формальное обоснование делает возможным использование интеллектуальных служб построения рассуждений, таких как автоматическая классификация и проверка целостности. Эти службы могут использоваться во время компиляции, облегчая таким образом построение повторно используемых, хорошо протестированных моделей предметной области. Службы логического вывода могут также использоваться во время выполнения в различных целях. Например, это позволяет определять классы динамически, переклассифицировать экземпляры во время выполнения и выполнять сложные логические запросы. Кроме того, OWL и RDF Schema не только основываются на логике, но и оперируют структурами, схожими с объектно-ориентированными языками, а следовательно могут быть эффективно интегрированы с традиционными программными компонентами.
В итоге, ключевые преимущества RDF Schema и OWL по сравнению с объектно-ориентированными языками заключаются в следующем:
- Повторное использование и взаимодействие: модели RDF и OWL могут совместно использоваться приложениями в сети
- Гибкость: модели RDF и OWL могут работать в открытых окружениях, в которых классы могут определяться динамически и т.д.
- Проверка целостности и качества различных моделей
- Построение рассуждений: OWL обладает высокой выразительностью, поддерживаемой средствами автоматического логического вывода
Обратите внимание, что некоторые из этих преимуществ, такие как проверка целостности и автоматическое построение рассуждений, может быть также достигнуто средствами Языка объектных ограничений (Object Constraint Language, OCL). OCL является частью семейства языков Группы управления объектами (Object Management Group, OMG) для архитектуры, основанной на моделях, и предоставляет сходную с современными языками семантической паутины выразительность. Например, ограничение, показанное на рисунке 1, могло бы быть выражено на языке OCL для формализации условий беспошлинных заказов. Однако, OCL не был разработан для Веб, но он оптимизирован для представления ограничений в рамках относительно замкнутых моделей данных. Техологии семантической паутины разработаны для мира открытых систем, в котором модели используются совместно различными приложениями и группами. Далее мы покажем, каким образом эта открытость проявляет себя в языках семантической паутины. Стоит отметить, однако, что различия между объектно-ориентированными языками и OWL вовсе не являются непреодолимыми. Фактически, рабочая группа OMG разработала Метамодель определения онтологий (Ontology Definition Metamodel) [ODM 2005] которая позволит разработчикам использовать языки семантической паутины в тандеме с другими форматами, такими как OCL.
Далее в этом документе мы собираемся объяснить, как объектно-ориентированные приложения могут быть спроектированы и реализованы с помощью технологий семантической паутины. Второй раздел даёт набросок того, какую выгоду жизненный цикл разработки ПО может извлечь из методов семантической паутины. Третий раздел представляет собой введение в языки семантической паутины RDF Schema и OWL, а также сравнивает их с языками объектно-ориентированного моделирования. Четвёртый раздел показывает, каким образом модели RDF и OWL могут быть встроены в объектно-ориентированные программы (в качестве примера используется Java). В Приложении указаны ссылки для дальнейшего чтения, а также на инструменты и библиотеки.
Разработка приложений с применением семантических веб-технологий
Что такое семантическая паутина? Большая часть текущего «традиционного» веб-содержимого предназначено для использования людьми. Языки представления, такие как HTML, содержат инструкции для веб-браузеров, сообщающие, как представлять мультимедиа-содержимое специально для нашего визуального и слухового восприятия. Однако, если бы мы захотели нанять компьютерную программу для поиска находящейся в Веб информации, то подобные методы столкнулись бы со сложностями в извлечении какого-либо смысла из этих веб-страниц, если бы у них не было продвинутых навыков в человеческих языках. Более того, современные серверные языки для Веб, такие как JSP или ASP, поддерживают случайную смесь моделей и видов в одном файле, что приводит к очень неструктурированному содержимому.
Представление, на которое опирается семантическая паутина, заключается в том, чтобы сделать веб-содержимое читабельным для машин таким образом, чтобы оно могло легче анализироваться программными агентами и распространяться среди веб-служб. В этих целях Консорциум Всемирной паутины (W3C) рекомендует несколько основанных на Веб языков, которые могут использоваться для формализации веб-содержимого. RDF Schema и OWL могут использоваться для описания классов, атрибутов и отношений подобно объектно-ориентированным языкам. Например, язык RDF Schema может быть использован для определения того, что у класса Product имеется свойство hasPrice принимающее значения в виде числа с плавающей точкой. Вы можете определить класс Purchase со свойством hasProducts которое соотносит его с различными объектами Product. OWL расширяет RDF-схему дополнительными конструкциями для определения более сложных классов. Например, OWL может использоваться для определения класса DutyFreeOrder как подкласса всех покупок, у которых в адресе доставки значится страна, о которой известно, что она входит в соглашение о беспошлинной торговле. W3C также работает над другими языками для описания правил вида «если-то» и сложных SQL-подобных запросов, но мы в данном обсуждении сконцентрируем наше внимание на RDF Схеме и OWL.
Модели предметной области с помощью любого из этих языков могут быть загружены и связаны во Всемирной паутине таким же образом, каким вы бы опубликовали HTML-страницу. Как только RDF или OWL файл оказался в сети, другие веб-ресурсы или приложения могут на него ссылаться. Например, HTML-страница, отображающая определённый продукт может включать метаданные, ссылающиеся на соответствующую сущность в модели OWL, так что все приложения, которые понимают, что такое «продукт», могут извлечь смысл и из HTML-страницы. Или поставщики определённых продуктов могут создавать экземпляры классов RDF-схемы, чтобы анонсировать своё портфолио торговым агентам в формате обмена, исключающем неоднозначность. Типичный сценарий для такого приложения семантической паутины показан на рисунке 2.
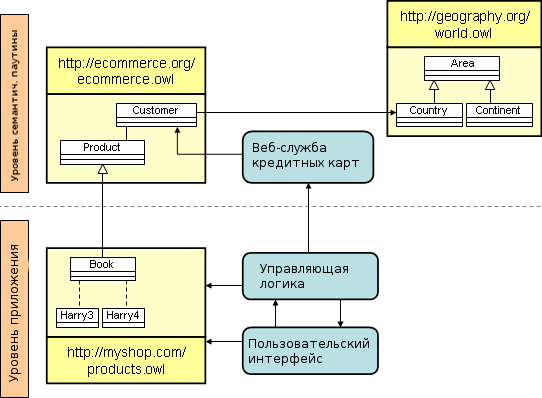
Рисунок 2: Приложение, использующее технологию семантической паутины, может эксплуатировать модели предметной области и веб-службы из Сети. Жёлтые прямоугольники изображают OWL-файлы в UML-подобной графической нотации. Обратите внимание, что нотация UML используется просто для примера — другие способы визуализации могут более подходящими для того, чтобы ухватить всю семантику OWL.
В то время как определённый уровень взаимодействия может быть также достигнут при использовании традиционных, основанных на XML, методов, языки семантической паутины имеют более богатую выразительность. Подобно объектно-ориентированным языкам, RDF Schema и OWL делают возможным объявление подклассов и обобщение концепций. Организация моделей предметной области в виде классов предполагает естественное отображение для интеграции моделей с оставшимися программными компонентами. Более того, поскольку каждый ресурс семантической паутины имеет уникальный URI, становится возможным устанавливать связи между существующими моделями. Это означает, что как только модель некоторой предметной области опубликована в Сети, другие модели потенциально смогут быть построены на её основе, таким образом формируя сеть дисциплинарных, а возможно и междисциплинарных знаний.
Расширяемость языков семантической паутины поддерживает возможность повторного использования в глобальных масштабах. Вместо определения 1000-ной вариации прикладной модели «продукт-покупка», разработчики приложения могут найти подходящую модель в Сети и просто использовать или расширить её. Используя существующую модель, различные приложения со схожими задачами могут обмениваться результатами и данными с большей лёгкостью. Более того, вероятно, что в них может быть интегрирована независимая от приложения повторно используемая компонента (такая как приложение потребительской корзины или веб-служба для кредитных карт). В то время, как обещание глобального обмена знаниями в Семантической паутине, возможно, оказывается слишком амбициозным для ближайшего будущего, RDF Schema и OWL по крайней мере предоставляют инфраструктуру для построения структур, повторно используемых среди заинтересованных сообществ. Детальное обсуждение этих проблем выходит за рамки данной статьи.
Обещанная возможность повторного использования частично объясняется тем фактом, что языки семантической паутины основаны на Веб: каждый класс, свойство или объект в RDF-схеме или OWL-файле имеет уникальный идентификатор (URI), так что на него можно ссылаться откуда угодно. Другая более сильная сторона, которая делает модели семантической паутины в значительной мере переиспользуемыми, заключается в том, что OWL основывается на формальной логике. Это означает, что модели OWL не ограничиваются одним только определением классов и их атрибутов, но могут также ограничивать потенциальное создание экземпляров этого класса таким образом, что эти классы могут явным образом распространяться среди групп людей и машин. Модели предметной области, основанные на столь подробно определённой логике, часто называют онтологиями. Фактически, аббревиатура OWL означает "Web Ontology Language" (язык веб-онтологий). В соответствии с [OWL 2004], OWL может использоваться для явного представления значений понятий в словарях и отношений между этими понятиями. Такое представление понятий и их взаимосвязей вновь является формой онтологии. С объектно-ориентированной точки зрения, онтологии являются классами предметной области, которые содержат логические утверждения, делающие их значение явным. Далее мы покажем, что инструменты, называемые механизмами рассуждений (reasoners) могут использовать эти логические утверждения для выполнения расширенных запросов, которые выявляют неявные связи между ресурсами.
Онтологии и модели предметной области часто охватывают разные уровни абстракции, зависимостей между приложениями и повторного использования. Возвращаясь к примеру из введения, утверждения 1 и 2 определяют структуры данных покупателя и покупки. Утверждения 3, 4 и 5 касаются определённых стран, которые могут использоваться в географических и политических приложениях. Утверждение 6 не зависит от этих конкретных стран и описывает общие отношения между странами, отвечающими конкретному критерию в предметной области. Эти части должны быть переиспользуемыми или использоваться повторно из стандартизированных решений. Фактически, онтологии зачастую определяются группами людей (таких как консорциум электронной коммерции или участниками национального геологического исследования) для того, чтобы установить взаимосвязь между элементами словаря предметной области в целях интеграции информации. Когда создана стандартизированная онтология стран и их отношений, больше нет необходимости изобретать её заново в каждом отдельном приложении. Более того, повторное использование существующих онтологий из Сети имеет преимущество, заключающееся в том, что приложение сможет более непосредственно извлекать выгоду из обновлений, таких как добавление новых стран.
Тем не менее, конкретная локализация покупателей и нашего онлайн-магазина является специфичной для нашего приложения и нуждаются в дополнительной подгонке. Такая подгонка может быть осуществлена добавлением конкретных подклассов и экземпляров. В том случае, если общие онтологии/модели не оптимизированы для целей конкретного приложения и потому нуждаются в адаптации или построении с нуля, могут использоваться инструменты моделирования предметной области (такие, как упомянутые в Приложении). Эти инструменты подходят для экспертов в предметной области, у которых есть небольшой или же полностью отсутствует опыт использования языков программирования. Сопоставимые с редакторами для UML, эти инструменты предоставляют визуальные редакторы классов и отношений и позволяют пользователям создавать экземпляры этих классов.
Деятельность по моделированию предметной области в рамках такого процесса разработки можно сравнить с анализом требований и проектированием в традиционной разработке программного обеспечения. Эксперты в предметной области и конечные пользователи объединяют свои усилия с проектировщиками ПО, разработчиками и тестировщиками для того, чтобы прийти к подходящим абстракциям прикладной области. Онтологии из Сети комбинируются, расширяются и инстанциируются. Средства разработки онтологий предоставляют удобства для создания экземпляров классов таким образом, что можно создавать и прототипировать экземпляры-примеры. Затем программисты комбинируют полученные модели предметной области с оставшимися компонентами приложения, такими как пользовательский интерфейс и управляющая логика. В отличие от многих традиционных объектно-ориентированных методологий, в которых анализ и проектирование приводят лишь к промежуточным артефактам для генерации кода, в рамках метода семантической паутины одни и те же модели используются на всех стадиях от анализа, проектирования и реализации до тестирования и даже во время выполнения. Онтологии, определённые на ранних стадиях, устанавливают классы во время реализации, и в то же время оригинальные модели остаются доступными, когда приложение исполняется. Формальная логика, входящая в состав онтологий, даже может затем быть использована для создания прецедентов тестирования. В том случае, если у моделей предметной области явная семантика времени выполнения, можно в дальнейшем использовать службы логического рассуждения. Мы рассмотрим этот момент более детально после того, как ознакомимся с основами RDF и OWL.
3 Введение в RDF Schema и OWL
Для претворения видения семантической паутины в жизнь W3C выпустил несколько спецификаций языков. RDF и его схема рассматривают базовую инфраструктуру для представления классов, свойств и экземпляров в веб-совместимом формате. OWL расширяет RDF-схему, дополняя её более богатой выразительностью. На данный момент оба языка поддерживаются инструментами, парсерами и прикладными программными интерфейсами (API). Этот раздел содержит введение в RDF Schema и OWL, а также сравнение их с объектно-ориентированными языками.
3.1 RDF и RDF Schema
RDF (Resource Description Framework - Каркас описания ресурсов) [RDF 2004] это основанный на Веб язык, который может использоваться для формального описания ассоциаций между ресурсами. Ресурсом может быть что угодно, снабжённое уникальным идентификатором ресурса (URI). Поскольку у них есть URL, то HTML-страницы, изображения и мультимедиа файлы являются ресурсами. В RDF ресурсами также могут быть классы, свойства и экземпляры. Например, такой URI как http://ecommerce.example.org/ecommerce.rdf#Product мог бы представлять класс в виде RDF-файла, и вы могли бы использовать этот URI, чтобы аннотировать веб-страницу какого-то конкретного продукта.
RDF всего лишь определяет базовый синтаксис для содержимого семантической паутины и обладает сериализацией в формате XML, что позволяет обмениваться моделями в Сети. RDF Schema определяет объектно-ориентированную модель для RDF. RDF-схема определяет представление классов, отношений наследования, свойств, типов данных и т.д. Например, следующий файл на языке RDF Schema объявляет класс Product и свойство hasPrice:
<rdf:RDF xml:base="http://ecommerce.example.org/ecommerce.rdf"
xmlns="http://ecommerce.example.org/ecommerce.rdf#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdfs:Class rdf:ID="Product"/>
<rdf:Property rdf:ID="hasPrice">
<rdfs:domain rdf:resource="#Product"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#float"/>
</rdf:Property>
</rdf:RDF
|
Рассмотрение подробностей RDF, RDF Schema и синтаксиса XML выходит далеко за рамки данной статьи. Для данного документа важными являются лишь несколько концепций. URI часто разбивают на пространство имён (namespace) и локальное имя (local name), где пространство имён может быть сокращено с помощью префиксной нотации. Например, rdfs:Class является сокращением для URI http://www.w3.org/2000/01/rdf-schema#Class в том случае, если префикс rdfs был объявлен в заголовке файла. Если префикс не указан (как в случае с "Product"), то будет использовано пространство имён по умолчанию для файла. Для того, чтобы упростить представление, в данном документе мы остановим внимание на этой короткой нотации, основанной на локальных именах.
Пространства имён можно сравнить с пакетами в объектно-ориентированных языках. Следовательно, можно считать, что представленный выше файл определяет пакет http://ecommerce.example.org/ecommerce.rdf#. Все ресурсы, объявленные в пространстве имён, являются общедоступными, чтобы все RDF-файлы могли ссылаться друг на друга напрямую. Например, вы могли бы создать другой RDF-файл, который определял бы экземпляр упомянутого выше класса Product и назначал бы этому экземпляру конкретную цену. Такие экземпляры в RDF называются индивидами. В отличие от многих объектно-ориентированных языков, индивиды могут быть отнесены напрямую более чем к одному типу. Например, индивид http://myshop.example.com/products.rdf#Harry может быть объявлен и как экземпляр http://ecommerce.example.org/ecommerce.rdf#Product, и как экземпляр http://auctioning.example.org/model.rdf#AuctionItem. Это позволяет использовать один и тот же ресурс (указанный через его URI) в одном контексте как продукт, а в другом контексте как лот аукциона.
В RDF Schema классы являются совокупностями индивидов с общими характеристиками. Классы могут быть организованы в иерархии наследования во многом подобно объектно-ориентированным системам. Как и UML, RDF Schema поддерживает множественное наследование. Основное различие между RDF и объектно-ориентированными языками, тем не менее, заключается в том, что классы могут пересекаться. Поскольку у индивида может быть несколько типов, некоторые экземпляры могут являться общими для нескольких классов. Более того, экземпляры могут менять свой тип в течение жизненного цикла. Заказ может начать своё существование как экземпляр класса PurchaseOrder, а затем сменить свой тип на DutyFreeOrder, когда программа соберёт больше информации об адресе доставки покупателю.
Другим важным различием между Семантической паутиной и объектно-ориентированными языками является то, Семантическая паутина является открытым миром, в котором файлы могут добавлять новую информацию о существующих ресурсах. Поскольку Всемирная паутина — это огромное пространство, в котором что-либо может ссылаться на что-либо ещё, невозможно выяснить, является ли некоторое утверждение верным или станет ли оно истинным в будущем. Например, если мы определяем класс, мы обычно не можем знать наперёд обо всех его экземплярах. Подобно этому, мы не можем вывести, что конкретный Product будет также использоваться и как лот AuctionItem. Это «предположение открытости» означает, что моделирование предметной области в семантической паутине может потребовать изменения в мышлении разработчиков, которые привыкли к закрытым, конечным предметным областям «классических» объектно-ориентированных систем или «традиционных» реляционных баз данных. С другой стороны, щедрым вознаграждением будет гибкость и обмен опытом как часть безграничного мира возможностей повторного использования и взаимодействия. В частности, метод «открытого мира» означает, что любая веб-ориентированная общедоступная онтология может добавлять подклассы или дополнительные характеристики к концепциям, определённым в других онтологиях, чтобы приспособить их для иного прикладного использования. В закрытых системах, таких как программы на языке Java, это не является ни легкодоступной, ни общепринятой практикой.
Однако вернёмся к языку RDF. Свойства RDF можно сопоставить с атрибутами, полями или концами ассоциации в объектно-ориентированных языках. Однако, если в UML и Java атрибуты относятся лишь к одному классу, то в RDF свойства являются отдельными сущностями, которые могут быть определены независимо от классов и использоваться в нескольких классах одновременно. Например, вы можете определить свойство hasPrice и затем присоединить его к тем классам, в которых цена имеет смысл. Это также позволяет использовать одно и то же свойство в различных файлах. Например, если вы создаёте модель программы онлайн-аукционов, вы могли бы использовать свойство цены из модели онлайн-магазинов для аналогичного представления цен лотов аукциона. Совместное использование одних и тех же свойств в различных моделях означает, что и значения могут быть легко интегрированы, к примеру, при сравнении текущей цены на аукционе с ценой нового продукта в других онлайн-магазинах.
Для того, чтобы «присоединить» или «ассоциировать» свойство с классом, используются высказывания rdfs:domain. Rdfs:domain — это тег из пространства имён RDF Schema, который относит свойство к классу с помощью предиката. В приведённом выше примере доменом для hasPrice является Product. По существу, с объектно-ориентированной точки зрения это означало бы, что у всех экземпляров класса Product могут быть связанные с ними значения цены (Price), таким образом делая Price атрибутом Product. Однако, в RDF и OWL у этого высказывания есть ещё дополнительный подтекст: любой ресурс, который является субъектом hasPrice, является экземпляром класса Product. Другими словами, высказывание о домене в RDF может использоваться для классификации сущностей. Следовательно, возвращаясь к нашему примеру, если у чего-либо есть цена, то его можно обрабатывать как экземпляр Product, даже если оно принимает участие в других объявлениях (или тройках, triples) — это ключевой момент, который будет рассмотрен более подробно позже в контексте логического вывода с помощью OWL.
Таким образом, простые значения, такие как цены, в RDF называются литералами, и литералы относятся к типу данных XML Schema, такому как xsd:string или xsd:float. Можно накладывать ограничения на значения свойств с помощью выражения rdfs:range. Свойство может в качестве диапазона принимаемых значений иметь либо тип данных XML Schema, либо класс. Свойства с классами в качестве диапазона можно сопоставить отношениям в объектно-ориентированных языках. Например, если свойство hasCustomer имеет диапазон Customer, то все значения свойства должны являться покупателями. Подобно выражениям доменов, выражения диапазонов могут интерпретироваться и другим путём: если мы знаем, что ресурс соотнесён с помощью свойства hasCustomer, то мы можем сделать умозаключение, что ресурс является фактически Customer, даже если у него есть другие типы.
3.2 OWL
Как было показано в предыдущих разделах, RDF Schema представляет собой простой язык моделирования предметной области, схожий с объектно-ориентированными языками. Вы можете определять классы и их свойства, а затем создавать экземпляры этих классов. Это бывает полезно для различных целей. Тем не менее, во многих прикладных областях выразительности одной лишь RDF Schema оказывается недостаточно. Например, RDF Schema не может выразить ограничения мощности множества, так чтобы у каждого продукта была только одна цена.
Язык веб-онтологий (Web Ontology Language, OWL) [OWL 2004] расширяет RDF схему и использует такой же RDF-синтаксис и его базовую грамматику. OWL добавляет возможность выражения информации о характеристиках свойств и определения классов путём группировки тех экземпляров, которые соответствуют этим характеристикам. Для того, чтобы лучше это понимать, важно помнить, что классы в OWL являются множествами аксиом. Как показано на рисунке 3, эти множества могут пересекаться и содержать другие множества.
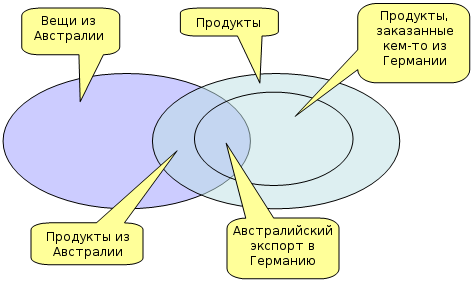
Рисунок 3: Классы в OWL могут рассматриваться как множества сущностей с общими характеристиками.
Круг слева на рисунке 3 описывает класс всех вещей, берущих своё начало в Австралии. Круг справа представляет все экземпляры класса «продукт». Следовательно, пересечение двух больших кругов представляет собой класс всех экземпляров, которые являются продуктами и в то же время «из Австралии», т.е. все австралийские продукты. Как показано маленьким кругом внутри круга продуктов, класс тех продуктов, которые заказал кто-то из Германии, является подмножеством всех продуктов. Наконец, множество всех австралийских продуктов, которые заказаны кем-то из Германии, представлено пересечением всех классов.
Не будем забывать о том, что свойства в RDF/OWL не зависят от отдельных классов и могут использоваться в нескольких местах. Например, свойство hasOrigin могло бы быть использовано для продуктов, людей, покупателей, музыки или чего угодно. Предполагая, что Australia где-то определена как экземпляр класса Country, кто-то мог бы теперь использовать OWL, чтобы формально определить класс всех вещей, для которых свойство hasOrigin имеет значение Australia. Тогда все экземпляры, определённые кем-либо ещё, могут быть классифицированы в соответствии с этим определением.
Элемент языка OWL, используемый для выражения таких определений, называется ограничение (restriction). Ограничение описывает класс всех экземпляров, свойство которых удовлетворяет некоторому конкретному условию. В OWL есть различные типы ограничений. В приведённом выше примере у нас есть так называемое ограничение имеетЗначение (hasValue), которое связывает свойство с конкретным индивидом. Другие условия ограничивают мощность множества для свойства, например, чтобы определить класс всех вещей, у которых есть по меньшей мере два значения свойства hasOrigin.
В данной статье вдаваться в подробности ограничений не обязательно. Ключевая сила OWL заключается в том, что классы могут определяться комбинацией нескольких ограничений и других классов. Для этих целей OWL предоставляет логические операторы для построения пересечений (и), объединений (или) и дополнений (не) других классов. Например, вы могли бы определить «класс всех покупателей из Франции, которые заказали не менее 3 покупок или сделали по меньшей мере один заказ, состоящий только из книг, за исключением тех покупателей, которые заказали DVD».
В объектно-ориентированных системах подобные высказывания обычно были бы спрятаны где-то внутри самого кода. В онтологиях семантической паутины логические отношения делаются явными через определения OWL-классов и другие формальные высказывания. Это не только облегчает пользователям моделей понимание специального смысла, но также означает, что и другие инструменты могут прозрачно использовать эти определения. OWL-модели просто объявляют вещи, а обязанность выполнения какой-либо полезной работы с этими объявлениями лежит полностью на плечах приложений.
Некоторые приложения семантической паутины могут использовать другие инструменты для обработки и анализа OWL-моделей. Одно из семейств таких инструментов называется механизмами рассуждений (reasoners). Механизм рассуждений — это служба, которая принимает высказывания, заключённые (утверждаемые) в онтологии и выводит (умозаключает) из них новые высказывания. В частности, блоки суждений OWL могут использоваться для:
- Выявления отношений «подкласс/суперкласс» между классами
- Определения наиболее конкретных типов индивидов
- Обнаружения не целостных определений классов
Итак, подходящий пример можно сформулировать следующим образом: представьте, что вы определили класс DutyFreeOrder, который состоит из всех PurchaseOrder, которые были заказаны покупателями, которые принадлежат к множеству покупателей, живущих в стране свободной торговли. Теперь представьте, что новый пользователь входит в онлайн-магазин и начинает класть предметы в свою потребительскую корзину. Внутри системы мы создадим пустые экземпляры классов Customer и PurchaseOrder. Позже, когда пользователь переходит к выписыванию покупки и вводит свой адрес доставки, мы можем попросить блок рассуждений классифицировать этот PurchaseOrder. Это позволит нам определить наиболее специфичный класс, к которому относится частный заказ (в данном случае это DutyFreeOrder). Тот факт, что теперь у нас имеется беспошлинный заказ, будет определяющим для дальнейшего жизненного цикла этого объекта, поскольку логика приложения может использовать дополнительные предметные знания о беспошлинных заказах.
В отличие от объектно-ориентированных систем, в которых объекты обычно не могут менять свой тип, приложения, построенные на основе технологии семантической паутины, могут следовать формальной и в то же время динамической системе типов. Классы RDF и OWL также динамические сами по себе, можно создавать их и манипулировать ими во время выполнения. Например, можно было бы определить временный класс, формально представленный в виде OWL-выражения, а затем спросить механизм рассуждений об экземплярах этого класса. Это означает, что механизмы рассуждений можно сравнить с расширенными системами ответов на запросы. Эти запросы можно задавать не только во время проектирования онтологий, но и во время исполнения.
3.3 Сравнение OWL/RDF с объектно-ориентированными языками
Подводя итог введению в RDF и OWL, следующая таблица показывает наиболее важные различия и сходства между языками семантической паутины и объектно-ориентированными языками:
|
Объектно-ориентированные языки |
OWL и RDF |
|
Модели предметной области состоят из классов, свойств и экземпляров (индивидов). Классы могут быть организованы в иерархии подклассов с применением наследования. Свойства могут принимать значения в виде объектов или примитивов (литералов). |
|
Классы и экземпляры
|
| Классы рассматриваются как типы экземпляров. |
Классы рассматриваются как множества индивидов. |
| У каждого экземпляра есть один класс в качестве типа. Классы не могут разделять экземпляры между собой. |
Каждый индивид может принадлежать к нескольким классам. |
| Экземпляры не могут менять свой тип во время выполнения. |
Членство в классе может меняться во время выполнения. |
| Список классов полностью известен на момент компиляции и после этого изменяться не может. |
Классы можно создавать и изменять во время выполнения. |
| Компиляторы используются во время сборки. Ошибки времени компиляции сигнализируют о проблемах. |
Механизмы рассуждений могут использоваться для классификации и проверки целостности во время выполнения или сборки. |
|
Свойства, атрибуты и значения
|
| Свойства объявляются локально для класса (и его подклассов с помощью наследования). |
Свойства являются отдельными сущностями, которые существуют безотносительно к конкретным классам. |
| У экземпляров могут быть значения только присоединённых свойств. Значения должны быть правильно типизированы. Ограничения диапазона используются для проверки типов. |
Экземпляры могут иметь произвольные значения любых свойств. Ограничения диапазонов и доменов могут использоваться для проверки и выведения типов. |
| Классы несут большую часть своего смысла и поведения в императивных функциях и методах. |
Классы делают свой смысл явным посредством OWL-высказываний. Императивный код к ним присоединён быть не может. |
| Классы могут инкапсулировать свои члены для частного доступа. |
Все части файла OWL/RDF общедоступны, и на них можно ссылаться откуда угодно. |
| Закрытый мир: если недостаточно информации для того, чтобы показать, что утверждение истинно, тогда оно предполагается ложным. |
Открытый мир: если недостаточно информации для того, чтобы показать, что утверждение истинно, тогда оно может быть как ложным, так и истинным. |
|
Роль в процессе проектирования
|
| Некоторые общие API используются приложениями совместно. Несколько (если они вообще есть) UML-диаграмм используются совместно. |
RDF и OWL были спроектированы для Веб методом «снизу вверх». Модели предметной области могут свободно распространяться в сети. |
| Модели предметной области проектируются как часть архитектуры приложения.
| Модели предметной области проектируются для представления знаний о предметной области и для информационной интеграции. |
| UML, Java, C# и т.д. являются зрелыми технологиями, поддерживаемыми многими коммерческими и открытыми инструментами. |
Семантическая паутина - развивающаяся технология с несколькими открытыми инструментами и небольшим количеством коммерческих поставщиков. |
|
Прочие особенности
|
| Экземпляры анонимны до такой степени, что на них непросто ссылаться из-за пределов выполняющейся программы. |
Все именованные ресурсы RDF и OWL имеют уникальный URI, посредством которого на них можно ссылаться. |
| Модели UML могут быть сериализованы в формате XMI, который используется для обмена между инструментами, но не является действительно веб-ориентированным. Объекты Java могут быть сериализованы в различных XML-подобных или естественных промежуточных форматах. |
Объекты RDF и OWL имеют стандартную сериализацию, основанную на XML, с уникальными URI для каждого ресурса внутри файла. |
4 Программирование с применением RDF Schema и OWL
Многие современные программные архитектуры состоят из объектно-ориентированных компонентов, реализованных на основных языках программирования, таких как Java или C#. В системах с толстым клиентом большая часть пользовательского интерфейса и управляющего кода будет написана с использованием объектно-ориентированных библиотек наподобие Swing или SWT. В клиент-серверной конфигурации, сервер может исполнять Enterprise JavaBeans (EJB), которые сообщаются с базами данных и другими ресурсами. В веб-сервисах большинство управляющей логики будет реализовано с применением императивных, объектно-ориентированных методов.
Для того, чтобы воспользоваться преимуществами технологии семантической паутины в контексте таких основанных на объектах систем, архитекторам программного обеспечения нужно понимать шаблоны проектирования и стратегии для бесшовной интеграции этих технологий. Пока мы только начинаем понимать значение технологии семантической паутины для проектирования систем и программного обеспечения, начинают появляться многие перспективные решения-кандидаты, включая программные интерфейсы и генераторы кода. В данном разделе мы сделаем обзор состояния дел (на момент написания этой заметки) в основанной на онтологиях разработке программного обеспечения, а также обсудим некоторые концепции, заложенные в её фундаменте.
Для того, чтобы понимать архитектуры, основанные на онтологиях, нужно помнить, что в языках онтологий:
- Свойства не зависят от отдельных классов
- Экземпляры могут иметь несколько типов и изменять свой тип в результате классификации
- Классы могут определяться динамически, во время выполнения
Эти ключевые различия означают, что недостаточно просто спроецировать классы OWL/RDF Schema на объектно-ориентированные классы, в которых атрибуты прикреплены к классам и т.д. Вместо этого, если приложение хочет воспользоваться слабой типизацией и гибкостью OWL/RDF Schema, необходимо спроецировать классы OWL/RDF Schema в объекты времени выполнения таким образом, чтобы классы в онтологии стали экземплярами некоторых объектно-ориентированных классов (сравните также [G 2003] и [KPBP 2004]). Как показано на рисунке 4, типичная объектная модель для представления онтологий семантической паутины содержала бы классы для представления ресурсов, классов, свойств и индивидов. Обратите внимание, что классы RDFSClass и RDFProperty относятся к классам rdfs:Class и rdfs:Property, определённым в RDF Schema, в то время как RDFIndividual не имеет прямого аналога в RDFSchema.
Легко представить дальнейшие расширения для различных типов OWL-классов (полную объектную модель OWL смотрите в Protege OWL Diagram).
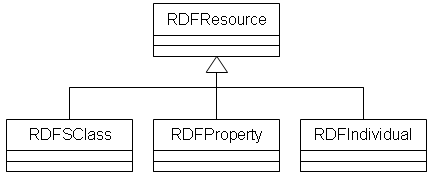
Рисунок 4: Простая объектно-ориентированная модель для представления онтологий RDF Schema.
Приложения будут загружать онтологии в такую объектную модель и затем манипулировать объектами и запрашивать их во время выполнения. Поскольку классы OWL/RDF Schema являются объектами, возможно добавлять и модифицировать их, например, чтобы изменить логические характеристики онтологии во время выполнения. Поскольку RDF-свойства являются объектами (и их значения не хранятся как объектно-ориентированные атрибуты), становится возможным присваивать и запрашивать значения любых ресурсов динамически. Поскольку индивиды являются объектами, можно динамически менять их тип.
Этот подход связан с методом разработки, известным в технологии промышленного производства программного обеспечения как шаблон динамической объектной модели (Dynamic Object Model, DOM) [RTJ 2005]. Для конкретных объектно-ориентированных систем представление типов объектов в виде объектов позволяет изменять их во время конфигурации выполнения, облегчая изменение и адаптацию системы к новым требованиям.
В сообществе семантической паутины несколько программных интерфейсов реализуют этот шаблон. Популярные библиотеки для Java, C и PHP перечислены в Приложении. В дополнение к интерфейсам динамической объектной модели эти библиотеки предоставляют парсеры, интерфейсы блоков рассуждения и прочие различные сервисы для обработки онтологий. Для того, чтобы у вас было представление об использовании таких библиотек, приведём следующий кусок кода на Java (метод, который считает сумму всех покупок заданного пользователя):
public static float getPurchasesSum(RDFIndividual customer) {
OWLModel owlModel = customer.getOWLModel();
float sum = 0;
RDFProperty purchasesProperty = owlModel.getRDFProperty("purchases");
RDFProperty productProperty = owlModel.getRDFProperty("product");
RDFProperty priceProperty = owlModel.getRDFProperty("price");
Iterator purchases = customer.listPropertyValues(purchasesProperty);
while(purchases.hasNext()) {
RDFIndividual purchase = (RDFIndividual) purchases.next();
RDFIndividual product = (RDFIndividual) purchase.getPropertyValue(productProperty);
Float price = (Float) product.getPropertyValue(priceProperty);
sum += price.floatValue();
}
return sum;
}
|
Это обобщённый и гибкий код, но в то же время у этого подхода есть некоторые недостатки. Если классы и свойства являются объектами, то преимущества систем с сильной типизацией не могут быть использованы во время компиляции. Таким образом, становится довольно неудобным осуществлять доступ к значениям свойств, и код становится перегружен инфраструктурными вызовами доступа к свойствам и т.д. К тому же, доступ к ресурсам осуществляется по именам, закодированным в виде строк, так что большинство компиляторов не могут помочь с обнаружением ошибок. С точки зрения объектно-ориентированной реализации, много более удачная реализация представленного выше метода выглядела бы так:
public class Customer extends RDFIndividual {
public float getPurchasesSum() {
float sum = 0;
Iterator purchases = listPurchases();
while (purchases.hasNext()) {
Purchase purchase = (Purchase) purchases.next();
Product product = purchase.getProduct();
sum += product.getPrice();
}
return sum;
}
}
|
Вместо доступа к абстрактному классу, такому как RDFIndividual и RDFProperty, мы бы осуществляли доступ к специально созданным классам, таким как Purchase и Product. К счастью, возможно генерировать и использовать такие классы, не принося в жертву преимущества динамической объектной модели. Генераторы кода могут принимать RDF-схему или OWL-онтологию на входе и создавать объектно-ориентированные интерфейсы и реализацию на выходе. Список некоторых подходящих генераторов представлен в Приложении. В предыдущем примере генератор создал бы Java-интерфейс Customer, определяющий методы get и set для свойств, у которых Customer указан в качестве домена (например, getEMail и setEMail). Эти интерфейсы являются подклассами обобщённых классов из программного интерфейса динамической объектной модели (такого, как RDFIndividual). Это означает, что экземпляры этих интерфейсов являются «обычными» объектами RDFIndividual, в то время как сгенерированные интерфейсы работают в качестве (необязательного) приспособленного слоя поверх них.
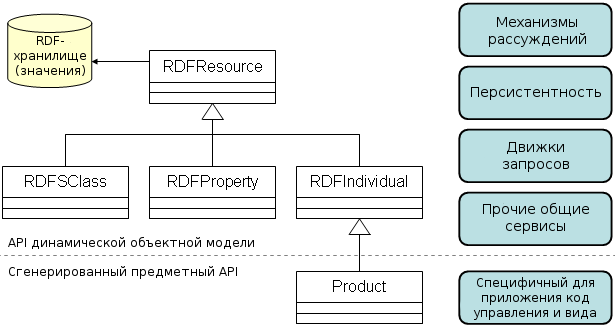
Рисунок 5: Модели семантической паутины могут быть доступны как через обобщённые API, так и с помощью специфичных для предметной области классов.
Тот факт, что объекты времени выполнения являются также экземплярами обобщённого, динамического API означает, что разработчики могут использовать для реализации два различных программных интерфейса в зависимости от задачи. Для общих сервисов, таких как построение суждений, парсинг, выполнение запросов и проверка ввода, возможно повторно использовать или писать код для API динамической объектной модели (DOM). Обобщённый код имеет огромный потенциал для повторного использования и предполагает, что всё больше и больше свободно доступных компонентов для обработки RDF и OWL появятся в будущем. Это замечание имеет некоторое значение для методологии разработки систем, основанных на онтологиях. В частности, если существуют общие компоненты для построения суждений и выполнения запросов, то проектировщикам ПО следует как можно больше информации заключать в модели предметной области на RDF/OWL, повышая таким образом уровень абстракции в этой области для произвольных служб. Например, тот факт, что заказы из стран с соглашением о беспошлинной торговле не облагаются пошлиной, мог быть реализован внутри тела метода, наподобие isDutyFree() в классе Java PurchaseOrder. Однако это сделало бы невозможным использование общих блоков рассуждения для автоматической классификации заказа. Более аккуратным решением было бы определить подкласс DutyFreePurchaseOrder в онтологии OWL и сопроводить его высказываниями в дискрипционной логике, которые определяют, каким образом беспошлинные заказы отличаются от остальных заказов. Доступность повторно используемых, обобщённых сервисов служит стимулом к построению моделей предметной области с явной семантикой.
Несмотря на обещания разработки программного обеспечения, основанного на онтологиях, также важно понимать, когда не следует использовать технологию семантической паутины. Что наиболее важно, у многих движков рассуждений, упомянутых в этом документе, на данный момент имеются проблемы с масштабируемостью и производительностью. Классификация произвольных онтологий OWL DL может быть чрезвычайно длительной задачей и может, таким образом, ограничить использование классификаторов во время выполнения. Производительность является менее критическим фактором, когда блоки рассуждений используются во время сборки онтологии.
Другие проблемы семантической паутины в целом связаны с пределами повторного использования онтологий. Строить действительно независимые от предметной области и пригодные для повторного использования онтологии сложно. Более того, онтологии зачастую сложны и дороги в построении, а значит представляют собой вложение, которое многие компании-производители ПО не стали бы просто загружать и делать свободно доступными в Сети. Эти проблемы выходят за рамки этой статьи, но их важно иметь в виду [BMT 2005].
Приложение: Куда следовать далее
- Ссылки на программные интерфейсы (API)
- Java
- C
- PHP
- Генераторы кода
- Ссылки на инструменты и инфраструктуру поддержки
- Ссылки на более детальные онлайн-документы
- Ссылки на примеры онтологий
- Ссылки на примеры приложений семантической паутины
Нормативные ссылки
- [BCCG 2004]
- Visual modeling of OWL DL ontologies using UML. Saartje
Brockmans, Andreas Eberhart, Raphael Volz, Peter Löffler In S.A. McIlraith
et al., Proceedings of the Third International Semantic Web Conference,
Hiroshima, Japan, 2004, pp. 198-213. Springer, November 2004.
- [BHS 2003]
- Description Logics. Baader, Franz, Horrocks, Ian, and Sattler,
Ulrike. Volume Handbook on Ontologies in Information Systems of International
Handbooks on Information Systems, chapter I: Ontology Representation
and Reasoning, pages 3-31. Steffen Staab and Rudi Studer, Eds., Springer.
2003. // Description Logics. Baader, Franz, Horrocks, Ian, and Sattler,
Ulrike. Volume Handbook on Ontologies in Information Systems of International
Handbooks on Information Systems, chapter I: Ontology Representation
and Reasoning, pages 3-31. Steffen Staab and Rudi Studer, Eds., Springer.
2003.
-
-
- [BMRSS 1996]
- Pattern-Oriented Software Architecture, Volume 1: A System of
Patterns. Buschmann, Frank, Meunier, Regine, Rohnert, Hans, Sommerlad,
Peter, and Stal, Michael. John Wiley and Son Ltd., 1996.
-
- [BMT 2005]
- Case Studies on Ontology Reuse. Elena Paslaru Bontas, Malgorzata
Mochol, Robert Tolksdorf. 5th International Conference on Knowledge Management
(I-Know=9205). 2005.
- [BCCG 2003]
- Reasoning on UML Class Diagrams. Berardi, D., A. Caly,
D. Calvanese, and G. De Giacomo TR-11-2003, Dipartimento di Informatica
e Sistemistica, Universita di Roma, La Sapienza (2003)
- [G 2003]
- Ontology-oriented programming: Static typing for the inconsistent
programmer. Neil M. Goldman. In 2nd International Semantic Web
Conference (ISWC 2003), Sanibel Island, FL, 2003.
-
- [KPBP 2004]
- Automatic mapping of OWL ontologies into Java. Aditya Kalyanpur,
Daniel Jimenez Pastor, Steve Battle, and Julian Padget.In 16th International
Conference on Software Engineering and Knowledge Engineering (SEKE), Banff,
Canada, 2004.
-
- [ODM 2005]
- Ontology
Definition Metamodel. OMG Ontology Working Group. 2005.
-
- [OWL 2004]
- Web
Ontology Language (OWL) Overview. McGuinness, Deborah L. and
van Harmelen, Frank. W3C Recommendation. 2004.
-
- [RDF 2004]
- RDF Primer.
Frank Manola, Erik Miller. W3C Recommendation. 2004.
- [RTJ 2005]
- Dynamic Object Model. Dirk Riehle, Michel Tilman, and Ralph
Johnson. In Dragos Manolescu, Markus Völter, James Noble (eds.) Pattern
Languages of Program Design5. Reading, MA: Addison-Wesley, 2005.
- [TPOWUK 2005]
- Ontology Driven Architectures and Potential Uses of the
Semantic Web in Software Engineering. Tetlow, Phil, Pan, Jeff,
Oberle, Daniel,Wallace, Evan, Uschold, Mike, and Kendall, Elisa. W3C Working
Draft. 2005
-
-
-
Благодарности
Этот документ является результатом труда Рабочей силы по разработке программного обеспечения Рабочей группы правил применения и развёртывания семантической паутины. Редакторы хотели бы поблагодарить следующих рецензентов за их полезные комментарии к этому документу: Грэди Буча, Джереми Кэрролла, Элизу Кендалл и Джона Мак-Клура.